Why use APIs ?
|
IBM API Connect, which integrates creating, running, managing, and securing APIs into one solution that can run on-premises and in the hybrid cloud. IBM API Connect is a complete API lifecycle management solution that will make things easier for developers, Central IT, and LoB Management. The thought behind API Connect is that APIs are small data applications, often called microservices, but they are applications nonetheless. APIs need to be created, tested, deployed, debugged, clustered, scaled, monitored, managed and administered. The actions in the lifecycle occur before organizations can use API management offerings to add and enforce policies to APIs for security. API Connect enables organizations to perform the actions in the API lifecycle efficiently, whilst avoiding the issues that commonly surround creating, running, updating, or scaling APIs separately from API management offerings.  With API Connect, the automated creation of APIs against enterprise back ends (WebSphere, IBM Integration Bus, IBM z, or non-IBM alternatives) hastens ‘time to market’. CIOs and Lines of Businesses can partner to unlock enterprise IT assets (apps and data in WebSphere, CICS, IBM Integration Bus) and the creativity of developers, without sacrificing security and governance across the API lifecycle. The integration of existing and new IT assets with Hybrid cloud licensing allows for seamless platform flexibility and lower cost of ownership. API Connect provides support for multiple development languages and frameworks along with unified management and administration of Node.js and Java.
Beyond the scope of the IT department, API Connect improves the rate of innovation for organizations, reach new customers with ease, and gain competitive advantages by facilitating rapid delivery of applications and services. For additional monetization, organizations can publish their APIs to select business partners or developer communities through the use of varying rate limit plans. Then, API Connect can analyze API usage and performance to improve the efficiency of the offerings. API Connect promotes visibility and consistency alongside development, operations and line-of-business teams, because is acknowledges that helping the organization better align technology strategy with business strategy is vital for success. Three editions of API Connect are available with flexible ordering options: • Essentials Essentials is a free offering for developers and businesses to provide the essential functionality to create, run, manage, and secure the consumption of APIs and Microservices. However, it does not include IBM support. • Professional Professional is designed for departmental use, because it provides the functions that are available in the Essentials edition, and adds the functionality to cluster a limited number of nodes within a single datacenter. • Enterprise Enterprise is designed for enterprises and includes a comprehensive set of enterprisegrade capabilities. It provides the functions that are available in the Professional edition, and adds a robust set of additional functionality. Enterprise also delivers support for the clustering of a large number of nodes within a single datacenter, and across multiple datacenters. Both the Professional and Enterprise editions are priced offerings that include support from IBM. IBM API Connect is planned to be made available on March 15, 2016 with flexible pricing for your various needs. We will share more in the upcoming weeks. To get details about how API Connect can help you be more productive and reduce dependence on IT as well as shorten development cycles Mule, the runtime engine of Anypoint Platform, is a lightweight Java-based enterprise service bus (ESB) and integration platform that allows developers to connect applications together quickly and easily, enabling them to exchange data. It enables easy integration of existing systems, regardless of the different technologies that the applications use, including JMS, Web Services, JDBC, HTTP, and more. The ESB can be deployed anywhere, can integrate and orchestrate events in real time or in batch, and has universal connectivity. The key advantage of an ESB is that it allows different applications to communicate with each other by acting as a transit system for carrying data between applications within your enterprise or across the Internet. Mule has powerful capabilities that include:
 Integration service is the accomplish engine for the Informatica, in other words, this is the entity which carry out the tasks that we create in Informatica. This is how it works
A user executes a workflow
For Informatica Power Center Online Training contact info@VirtualNuggets(dot)com For example, it can combine data on or after an oracle table and a flat file source. So, in summary, Informatica integration service is a process residing on the Informatica server waiting for tasks to be assigned for the execution. When we execute a workflow, the integration service receives a notification to execute the workflow. Then the integration service reads the workflow to know the details like which tasks it has to execute like mappings & at what timings. Then the service reads the task details from the repository and proceeds with the execution. Sources & Targets Informatica being an ETL and Data integration tool, you would be always handling and transforming some form of data. The input to our mappings in Informatica is called source system. We import source definitions from the source and then connect to it to fetch the source data in our mappings. There can be different types of sources and can be located at multiple locations. Based upon your requirement the target system can be a relational or flat file system. Flat file targets are generated on the Informatica server machine, which can be transferred later on using ftp. Relational– these types of sources are database system tables. These database systems are generally owned by other applications which create and preserve this data. It can be a Customer Relationship Management Database, Human Resource Database, etc. for using such sources in Informatica we either get a replica of these datasets, or we get select privileges on these systems. Flat Files - Flat files are most common data sources after relational databases in Informatica. A flat file can be a comma separated file, a tab delimited file or fixed width file. Informatica supports any of the code pages like ascii or Unicode. To use the flat file in Informatica, its definitions must be imported similar to as we do for relational tables. Zero Downtime (ZDT) is an upgrade process that you can use to upgrade the Informatica MDM Hub hardware or software whereas provided that uninterrupted right to use to the MDM Hub. Batch and Services Integration Framework (SIF) user development can run throughout the ZDT upgrade process.
If you upgrade from a pre-9.5.0 version of Informatica MDM Multidomain Edition, the ZDT upgrade process consists of a readiness cycle and an upgrade cycle. The ZDT readiness cycle is similar to the ZDT advance cycle. However, the ZDT readiness cycle does not change the schema and does not migrate the data. The readiness cycle is a separate cycle from the upgrade cycle because the combined readiness and upgrade cycles may produce too many GoldenGate logs to replay. For Informatica MDM Online Training Contact VirtualNuggets(dot)Com If you upgrade from a post-9.5.0 version of MDM Multidomain Edition, the ZDT upgrade process just consist of the upgrade cycle. ZDT uses a duplicate inactive environment to perform the upgrade while letting the active environment provide for user processing. Golden Gate is the tool that provides replication from the active environment to the passive environment. The ZDT upgrade process upgrades the passive environment so that there is no impact to the active environment. ZDT provides multiple interfaces to allow exchange between environments and to allow for message between the environments. Any change made to the MDM Hub through the upgrade does not impact the ability to replicate changes from the active environment. Backfill mechanisms handle any impact to the MDM Hub metadata caused by the upgrade. Prerequisites for ZDT Earlier than you upgrade the MDM Hub with ZDT, confirm that you installed the right Golden Gate version: MDM Hub Version - 9.0.1 to 9.7.1 Supported GoldenGate Version - GoldenGate 11.2.1 MDM Hub Version - 9.7.1 or later Supported GoldenGate Version - GoldenGate 12.1.2.1 Upgrade with Zero Downtime Overview Perform the readiness cycle and upgrade cycle to upgrade from a pre-9.5.0 version of MDM Hub to a post-9.5.0 version of MDM Hub. You do not need to make the readiness cycle if you only upgrade the hardware, upgrade non-MDM software, upgrade the ORS schema, or apply an EBF or hotfix. You also do not require to perform the readiness cycle if you upgrade from a post-9.5.0 version of MDM Multidomain Edition. Zero Downtime readiness cycle You must run the readiness cycle when you upgrade from a pre-9.5.0 version of the MDM Hub software to a post-9.5.0 version. The readiness cycle contains the steps to recognize the data problem that you must resolve before proceeding to the Zero Downtime (ZDT) upgrade cycle. The readiness cycle does not need backfill after completion. You must complete the steps controlled from the passive environment before you continue to the steps controlled from the active environment. After the readiness cycle is complete, switch the environments to make the passive environment the active environment. Zero Downtime upgrade cycle Run the steps for the ZDT upgrade cycle from a command line interface, such as shell scripts, or a command-line job scheduler. The upgrade runs from a single flow of control to allow for almost full automation of the upgrade process. The ZDT upgrade cycle procedure provides steps for messaging between the active environment and passive environment, preserve replication control, and integrating backfill. If you upgrade from a pre-9.5.0 version of MDM Multidomain Edition, the Zero Downtime upgrade cycle modify the schema data structure and migrates the data. It is over-simple to communicate of data to facilitate is “bad” or “wrong.” Even data of cooperation quality is valuable, and the quality and value of your data can nearly always be improved through a successful quality management system.
The quality of the data records in your datasets can be express according to six key criteria, and a useful quality management system will allow you to assess the quality of your data in areas such as below: ♦ Completeness. Apprehensive with missing data, that is, with fields in your dataset that have been left unfilled or whose default values have been missing unchanged. (For example, a date field whose default setting of 01/01/1900 has not been edited.) ♦ Conformity. Disturbed with data values of a similar type that have been entered in a puzzling or impracticable manner, e.g. numerical data that includes or omits a comma separator ($1,000 versus $1000). ♦ Accuracy. Concerned with the general exactness of the data in a dataset. It is typically verified by comparing the dataset with a reliable reference source, for example, dictionary files contain product reference data. ♦ Consistency. Concerned with the occurrence of dissimilar types of data record in a dataset created for a single data type, e.g. the combination of personal and business information in a dataset intended for business data only. For Informatica Data Quality Online Training Contact info@VirtualNuggets(dot)Com ♦ Integrity. Concerned with the recognition of significant associations among records in a dataset. For example, a dataset may contain records for two or more individuals in a household but provide no means for the organization to recognize or use this information. ♦ Duplication. Concerned with data records that duplicate one another’s information, that is, with identifying outmoded records in the data set. (The list above is not absolute; the characteristics above are sometimes described with other terminology, such as redundancy or timeliness.) The accuracy factor differs from the other five factors in the following respect: whereas (for example) a pair of duplicate records may be visible to the naked eye, it can be very difficult to tell simply by “eye-balling” if a given data record is incorrect. Data Quality’s capabilities include difficult tools for recognize and resolving cases of data inaccuracy. The data quality issues above relate not simply to poor-quality data, but also to data whose value is not being maximized. For example, duplicate householder information may not require any amendment per se — but it may indicate potentially profitable or cost-saving relationships among consumers or product lines that your organization is not exploiting. Every organization’s data needs are different, and the prevalence and relative priority of data quality issues will differ from one organization and one project to the next. These six characteristics represent a critically useful method for measuring data quality and resolving the issues that prevent your organization from maximizing the potential of its data. By default, Informatica Data Quality installs to C:\Program Files\Informatica Data Quality and adds a program group to the Windows Start menu. inside this program group is the Executable shortcut to Workbench. To start Workbench, select this shortcut (e.g. Start > Programs > Informatica Data Quality > Informatica Data Quality Workbench). For Live Informatica IDQ Online Training Contact info@VirtualNuggets(dot)Com 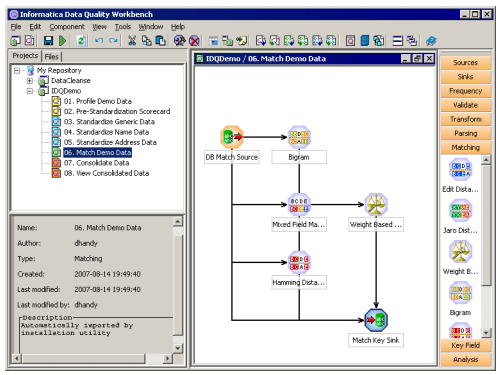 The Workbench user interface shows tabs to the left for the Project Manager and File Manager and a workspace to the right in which you’ll design plans. The fifty data components that you can use in a plan are shown on a dockable panel on the right-hand side. There are three basic types of component: Data Sources: which define the data inputs for the plan. Sources can connect to files or database tables. Operational Components: which perform data analysis or data transformation operations on the data. Many operational components make use of orientation dictionaries when analyzing or transforming data; dictionaries are explained below. Data Sinks which classify the data outputs that will be written to file or to the database. A plan must have at least one data source and data sink. A distinctive plan will also contain multiple operational components. The component palette displays the components available as octagonal icons that can be added to the plan workspace by mouse-click. The icons are according to the type of operation the component performs, below headings such as Analysis, Parsing, and Matching. Data sources, operational components, and sinks act as links in a chain to pass information from start to finish within a plan: a component is not active within a plan if not it has been configured to accept inputs from and give outputs to other components in this chain. Active components are associated to one another by arrowed lines, showing the approximate flow of data along the chain Copying Plans in the Data Quality Repository If you want to look at the functionality of a data quality plan, it is good practice to copy the plan to a new location in the Data Quality depository so that the original plan cannot be damaged. This section describes how to copy the installed plans within the repository for testing/learning purposes, and steps you can take to modify them in Data Quality Workbench. The main steps are as follows: ♦ Create a new project in Data Quality Workbench ♦ Copy or import more plans to this project ♦ Rename the project and imported plan(s) ♦ Change the data source associated with the plan Create a new project in Data Quality Workbench by right-clicking My Repository under the Projects tab and selecting New > Project from the context menu.  You can rename or remove the four folders default-created beneath this project.
Duplicate or import one or more plans to this project: You can make a copy of a plan inside the Project Manager by highlighting the plan name and typing Ctrl+C. You can then paste the plan to the project you have just created by right-clicking the project name and selecting Paste from the context menu. You can also import a plan file in PLN form or XML format from the file system. This may be suitable if you have received pre-built plans from Informatica, in which case backup copies of the plans may be installed to your file system. ♦ for more information on importing plans, see the Informatica Data Quality User Guide. Rename the project and imported plan(s): You should give names to your new project and plans that clearly distinguish them from the installed data quality project. To rename a project or plan, right-click it in the project structure and select Rename from the context menu. The name is highlighted and a flashing cursor indicates that it is editable: replace the old name with a new name and click elsewhere onscreen to commit your changes. Change the data source associated with the plan: This enables you to define a flat file as input for the plan, so that you do not need to provide real-time inputs each time the plan is run. Two New Languages
The first maintenance release for SAS 9.4 enables you to use the SPD Engine to read, write, and update data in a Hadoop come together through the HDFS. In addition, you can now use the HADOOP process to submit configuration properties to the Hadoop server. In the second maintenance release for SAS 9.4, performance has been improved for the SPD Engine access to Hadoop. The SAS Hadoop Configuration Guide for Base SAS and SAS/ACCESS is available from the support.sas.com third-party site for Hadoop. In the third maintenance release of SAS 9.4, access to data stored in HDFS is enhanced with a new distributed lock manager and therefore easier access to Hadoop clusters using Hadoop configuration files. Execute the DATA Step in New Supported Environments In the first maintenance release for SAS 9.4, the DATA step runs in In-memory in the SAS LASR Analytic Server and inside Hadoop using SAS/ACCESS and the SAS Embedded Process, with limits. Note that the DATA step processing in Hadoop is preproduction. For more information, see SAS LASR Analytic Server: Reference Guide and SAS In-Database Products: User's Guide. In the second maintenance release for SAS 9.4, DATA step process in Hadoop is fully supported. Improved Performance
As you specify which data members to include in an analysis, you create selections of data from the data source. Each selection specifies the criteria for a set of members for a particular column, such as Product or Geography. Each selection consists of one or more steps. A step is an instruction that affects the selection, such as add Product members whose values contain the text "ABC." The order in which steps are performed affects the selection of data. Each step acts incrementally on the results from previous steps, rather than acting on all the members for that column of OBIEE.
You can view these selection steps in the "Selection Steps pane". Steps are created using the following means: When you add a column to an analysis, a selection step is created automatically to start with all members, unless you explicitly add specific members. As you drag and drop column members in the Results tab to add to the analysis, steps are also created automatically. For example, suppose that you drag and drop the FY2007 and FY2008 members from the Year hierarchical column to a pivot table. The selection step "Add FY2007, FY2008" is created. For Instructor Led Live OBIEE Online Training contact info@VirtualNuggets(dot)com As you add groups and calculated items, steps are created automatically. When you use right-click interactions to refine the selection of data for a particular hierarchical column or attribute column, steps are created automatically. You can create steps directly using the Selection Steps pane, to refine the selection of data for a particular hierarchical column or attribute column. You can display the Selection Steps pane from various places including the Results tab, the Criteria tab, and some view editors. Selection steps can be one of the following types: Explicit list of members - A step can include a list of members for a column, such as Boston, New York, Kansas, South. For hierarchical columns, the members can be from different hierarchy levels. For attribute columns, the members can be from only that column. Condition step - A step can specify that members are selected from a column based on a condition, which can be one of various types including based on measures or on top/bottom values. This member list is dynamic and determined at run-time in Oracle Business Intelligence Enterprise Edition. Based on hierarchy step - A step for hierarchical columns that enables you to select the type of relationship with which to select members. You can select a family relationship (such as children of or parent of), a specific hierarchy level (for level-based hierarchies only), or a level relationship. Groups and calculated items - A step can include a group or calculated item. Groups and calculated items can be used only with Add steps; they cannot be used in Keep Only or Remove steps. For information, see 'Working with Groups and Calculated Items'. Creating Selection Steps You create steps in the "Selection Steps pane", which you can display in various places. The following procedure describes how to create steps in the Results tab. To create selection steps: Display the "Analysis editor: Results tab". If the Selection Steps pane is not visible, then click the Show Selection Steps pane button on the toolbar to display it. The pane might also be collapsed at the bottom of the Results tab. Click the plus sign icon to expand it. For the column whose steps you want to define, click the Then, New Step link. From the menu, select the option for the step type to create and complete the resulting dialog. Selection steps are automatically created when you use the right-click interactions (such as Add Related or Keep Only) to refine the selection of data for a particular hierarchical column or attribute column in a view. See "Right-Click Menu for Tables, Pivot Tables, and Trellises". After you add selection steps to the analysis, you can go to the "Analysis editor: Results tab" and add the Selection Step view to the analysis. If you add the Selection Steps view, at runtime the user can view the selection steps that are applied to the analysis. For more information about adding the selection steps view, see "Results tab: Selection Steps editor". Editing Selection Steps You can edit existing selection steps, as described in the following procedure. To edit selection steps: Hover the mouse pointer over the step in the Selection Steps pane and click a button on the resulting toolbar. You can perform various tasks such as displaying a dialog for editing the step, deleting the step, or changing the order of the step in the list of steps. For a group or calculated item, click its name to display a menu with options for editing and saving. Saving Selection Steps as a Group Object If you have created a set of selection-steps, then you can save and reuse the set as a group object, as described in 'Saving Groups and Calculated Items as Inline or Named'. Working with Selection Steps and Double-Columns If your repository is configured for double-columns, then you can create a selection step on a double column. To do so, select the display values for that column and the step is automatically evaluated using the code values that correspond to those display values. If you use double columns, then use care with the "New Calculated Item dialog". You can include a positional operator in the custom formula for the calculated item, such as $1, which specifies the column from the first row in the data set. When you include a positional operator, the display values cannot be mapped to the code values when evaluating the formula. This chapter explains how to construct filters, selection steps, groups, and calculated items in Oracle Business Intelligence Enterprise Edition. It explains how to use these objects to specify the data that is displayed in analyses and dashboards.
This chapter includes the following sections : Saving Objects as Inline or Named This section describes saving objects as inline or named. It contains the following topics: "What are Inline or Named Objects?" "What is the Folder Structure for Named Objects?" "Saving Filters as Inline or Named" "Saving Groups and Calculated Items as Inline or Named" For Instructor Led Live OBIEE Online Training Contact info@VirtualNugget(dot)com What are Inline or Named Objects? As you work with certain objects, you can create other objects that are saved with those objects. When you save one object with another, that object is saved "inline." You can save filters, groups, and calculated items inline. For example, you can create a group as part of an analysis. When you save the analysis, the group is saved "inline" or along with the analysis. In addition to saving these objects inline, you can save them as individual objects with the subject area in the Oracle BI Presentation Catalog. When you save an object on its own, its becomes a "named" object. Named objects provide reusability, because you can create one object and use it multiple times with any analysis, dashboard (for filters), or dashboard page (for filters) that contains the columns that are specified in the named object. When the named object is updated and saved, those updates are immediately applied to all objects where the named object is used. For example, after you save a group in line with an analysis, you can save the group as its own object in the catalog. You can then apply that named group from the Catalog pane to other analyses. What is the Folder Structure for Named Objects? Named filters, groups, and calculated items are generally saved to their related subject area folder. By saving the objects to a subject area folder, you ensure that they are available when you create an analysis for the same subject area. Named objects saved in the /My Folders folder are available only to you. Objects saved in the /Shared Folders folder are available to other users who have permission to access the folders. If a subject area folder does not exist in your /My Folders folder or within the /Shared Folders folder, then the subject area folder is created automatically. When you save the object, the "Save As dialog" displays a default save path to /My Folders/Subject Area Contents/<subject area>. However, the dialog's Folders area continues to display all instances of the subject area folder in the catalog. Saving Filters as Inline or Named When you create an inline filter in the Analysis editor: Criteria Tab's "Filters pane", you can optionally save the inline filter as a named filter. Named filters can also be created at the analysis level or as a standalone object from the global header. A named filter can filter all or some of the analyses that are embedded in a dashboard or analyses that are embedded on the same dashboard page. Saving Groups and Calculated Items as Inline or Named You can save groups and calculated item as an inline or named object: When you create a group or calculated item while editing and saving a view or while working in the "Compound Layout", the group or calculated item is saved inline with the analysis. When you work in the Selection Steps pane: You can save a group or calculated item that is within a step as a named object in the catalog. You can save a set of steps or the resulting members list for a column as a named object. You cannot save a set of steps as a group if one of the steps includes a calculated item. See "Adding a Group to Another Analysis" for information on adding a saved group to an analysis of OBIEE. To save a calculated item or group as a named object to the catalog: Display the "Selection Steps pane". Click the link for the calculated item or group, then click Save Calculated Item As or Save Group As to display the "Save As dialog". Complete the dialog to save the object to the catalog. To save a set of steps as a group to the catalog: Display the "Selection Steps pane". Click the Save Selection Steps button to the far right of the column name. Complete the "Save Selection Steps dialog" to save the group as an object to the catalog. What are Filters and Selection Steps? You use both filters and selection steps to limit the results that are displayed when an analysis is run, so that the results answer a particular question. Together with the columns that you select for an analysis, filters and selection steps determine what the results contain. Based on the filters and selection steps, only those results that match the criteria are shown. For example, depending on the industry in which you work, you can use filters and selection steps to learn who are the top ten performers, what are the dollar sales for a particular brand, which are the most profitable customers, and so on. Another kind of filter, called a prompt, can apply to all items in a dashboard. Prompts can be used to complete selection steps and filters at runtime. For information, see Chapter 6, "Prompting in Dashboards and Analyses." Oracle BI Enterprise Edition provides the Filters view and Selection Steps view, which you can add to an analysis to display any filters or selection steps applied to the analysis. Adding these views can help the user understand the information displayed in the analysis. For more information about how to add views to an analyses, see Chapter 3, "Adding Views for Display in Dashboards". How Do Filters and Selection Steps Differ? Filters and selection steps are applied on a column-level basis and provide two methods for limiting the data in an analysis. A filter is always applied to a column before any selection steps are applied. Steps are applied in their specified order. Filters and selection steps differ in various ways. Filters Filters can be applied directly to attribute columns and measure columns. Filters are applied before the query is aggregated and affect the query and thus the resulting values for measures. For example, suppose that you have a list of members in which the aggregate sums to 100. Over time, more members meet the filter criteria and are filtered in, which increases the aggregate sum to 200. Selection Steps Selection steps are applied after the query is aggregated and affect only the members displayed, not the resulting aggregate values. For example, suppose that you have a list of hierarchical members in which the aggregate sums to 100. If you remove one of the members using a selection step, then the aggregate sum remains at 100. You can create selection steps for both attribute columns and hierarchical columns. Selection steps are per column and cannot cross columns. Because attribute columns do not have an aggregate member, the use of selection steps versus filters for attribute columns is not as distinctive as for hierarchical columns. While measure columns are displayed in the Selection Steps pane, you cannot create steps for them so steps do not affect them. Measures are used to create condition steps for attribute and hierarchical columns, such as Sales greater than $1 million. Applying Filters to Attribute Columns to Affect Hierarchical Columns You can use a filter on a related attribute column to affect the display of members in a hierarchical column. For example, suppose a hierarchical column contains the levels Year, Quarter, and Month. Suppose that a filter exists on the attribute column that corresponds to the Year hierarchy level. If you create a filter on Year to limit it to 2008 and 2009, then when the hierarchical column is displayed in a view, only those two years are visible. This functionality depends on the way that the logical columns have been defined in the business layer of the subject area in the Oracle BI |
Archives
March 2017
AuthorWrite something about yourself. No need to be fancy, just an overview. 
Categories
All
|
 RSS Feed
RSS Feed